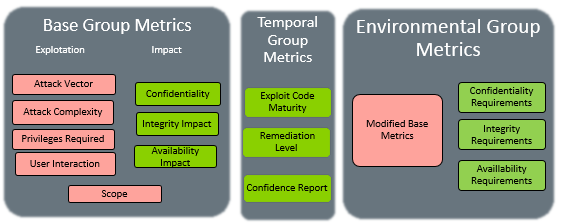
Vimos um resumo do entendimento do cálculo Base do CVSS 3.0. Após este cálculo, a pontuação pode ser refinada com a pontuação das métricas Temporal e Environmental para refletir com mais precisão o risco representado por uma vulnerabilidade no ambiente de um usuário. No entanto, elas não são obrigatórias. (mais…)
Pentest
Padronizando a pontuação das vulnerabilidades com CVSS 3.0

O Common Vulnerability Scoring System (CVSS) é uma forma identificar as principais características de uma vulnerabilidade e calcular uma pontuação numérica que reflita sua gravidade, bem como uma representação textual dessa pontuação. A partir da pontuação numérica, podemos traduzir em uma representação qualitativa (como baixa, média, alta e crítica) para ajudar as organizações a avaliar e priorizar adequadamente seus processos de gerenciamento de vulnerabilidades. (mais…)
Sugestões de livros para a certificação EC-Council CEH

Recentemente consegui obter a certificação CEH da EC-Council no modelo Self-study e muitas pessoas me pediram sugestões de livros para a preparação, então seguem abaixo algumas sugestões: (mais…)
Ataques de computação em nuvem

No mundo da computação em nuvem, vários ataques podem ser empregados contra um alvo. Muitos deles são variações ou são os mesmos que você já viu, mas existem alguns com uma roupagem nova. Muitos dos ataques que exploraremos aqui podem ser executados contra qualquer um dos modelos de serviço em nuvem mencionados anteriormente sem qualquer variação. (mais…)
Ameaças à segurança na nuvem

Os ambientes de nuvem não significam menos problemas relacionados à segurança. Muitas das mesmas questões de ambientes tradicionalmente hospedados existem na nuvem. A segurança na nuvem deve ser tratada com muita seriedade, tão seriamente quanto em qualquer outra situação em que você tenha serviços de críticos, dados importantes e processos de negócios dos quais você depende para manter as coisas em movimento. Para entender os tipos de ameaças que existem na nuvem e como eles podem afetar seu ambiente, veremos uma lista de problemas de segurança que são universalmente reconhecidos como sendo os maiores, mas não os únicos enfrentados pelos ambientes na nuvem: (mais…)
Técnicas de evasão do firewall

Vimos o que um firewall é capaz de fazer e os diferentes tipos que existem. Então, como um invasor pode evadir desses dispositivos? Existem algumas técnicas disponíveis para isto.
Spoofing de endereço IP
Uma maneira eficaz como um invasor pode evadir um firewall deve parecer como algo mais, como um host confiável. Usando o spoofing para modificar informações de endereço, o atacante pode fazer com que a fonte de um ataque pareça vir de algum lugar que não seja uma parte mal-intencionada.
Embora este ataque pode ser eficaz, existem algumas limitações que podem frustrar este processo. O mais óbvio é o fato de que firewalls mais do que provavelmente irão dar drop no tráfego. Especificamente, um host confiável pode ser algo dentro da própria rede. Qualquer tipo de pacote especialmente criado a partir de um intervalo de endereços IP na rede local, mas vindo de fora da rede, será descartado como inválido. (mais…)
Técnicas de evasão de IDS

Uma vez que você, como um pentester, está tentando testar a segurança de um sistema, você deve ser capaz de contornar esses dispositivos de proteção, se possível ou pelo menos saber como tentar fazê-lo. Veremos os vários mecanismos disponíveis, como eles funcionam e com quais dispositivos eles são projetados para lidar. (mais…)
Honeypots

Um dos sistemas mais interessantes que você vai encontrar é um honeypot. Na verdade é um dispositivo ou sistema usado para atrair e capturar atacantes que estão tentando obter acesso a um sistema. No entanto, honeypots estão longe de ser apenas uma armadilha. Eles também têm sido usados como ferramentas de pesquisa, armadilhas, e apenas para obter informações. Eles não são projetados para resolver qualquer problema de segurança específico.
Honeypots não se encaixam em qualquer classificação ou categoria. Honeypots pode cumprir uma série de finalidades diferentes ou funções para uma organização, mas a maioria concorda que um honeypot fornece valor de ser utilizado por partes não autorizadas ou através do uso ilícito. Honeypots são projetados para ser mal utilizado e abusado e nesse papel eles estão sozinhos. Na prática, o sistema pode aparecer como qualquer um dos seguintes:
- Um servidor dedicado
- Um sistema simulado de algum tipo
- Um serviço em um host projetado para parecer legítimo
- Um servidor virtual
- Um único arquivo
Identificando o firewall

Para determinar um tipo de firewall e até mesmo o fabricante, você pode usar sua experiência com scanner de portas e ferramentas para criar informações sobre o firewall que seu alvo está executando. Ao identificar determinadas portas, você pode vincular os resultados a um firewall específico e, a partir desse ponto, determinar o tipo de ataque ou processo a ser executado para comprometer ou ignorar o dispositivo.
Alguns firewalls como o Check Point FireWall-1 e o Microsoft Proxy Server usam as portas TCP 256-259 e TCP 1080 e 1745.
Felizmente, você pode realizar o banner grabbing com Telnet para identificar o serviço em execução em uma porta. Se você encontrar um firewall com portas específicas em execução, isso pode ajudar na identificação. É possível pegar o banner e ver o que é respondido de volta. (mais…)
Firewalls

Os firewalls são outro dispositivo protetores para redes que estarão no caminho de um pentester ou atacante. Os firewalls representam uma barreira ou delineamento lógico entre duas zonas ou áreas de confiança. Em sua forma mais simples, a implementação de um firewall representa a barreira entre uma rede privada e uma rede pública, mas as coisas podem ficar muito mais complicadas a partir daí.
Para a maior parte, nós nos referimos a firewalls como um conceito abstrato, mas na vida real um firewall pode ser um software ou um dispositivo de hardware.
Ao discutir firewalls, é importante entender como eles funcionam e sua colocação em uma rede. Um firewall é um conjunto de programas e serviços localizados no ponto de bloqueio, conhecido por choke point (o local onde o tráfego entra e sai da rede). Ele foi projetado para filtrar todo o tráfego fluindo para dentro e para fora e determinar se esse tráfego deve ser autorizado a continuar. Em muitos casos, o firewall é colocado a uma distância de recursos importantes para que, no caso de comprometer recursos-chave não são afetados negativamente. Se você tomar cuidado o suficiente e fazer o planejamento adequado, juntamente com uma dose saudável de testes, apenas o tráfego que é explicitamente permitido passar será capaz de fazê-lo, com todos os outros tráfego será negado no firewall. (mais…)