A globalização tornou os mercados mundiais cada vez mais dinâmicos e competitivos. O risco do negócio está mais claro e evidente para uma organização, e a necessidade de cumprir prazos e entregar produtos com qualidade é uma realidade nesse novo mundo.
A antecipação à resolução de um problema ou incidente é talvez, hoje, um dos maiores diferenciais para o sucesso do negócio da organização. Ou seja, antecipar- se a uma possível falha de TI, greves, falhas humanas, desastres naturais, por exemplo, é necessário, pois nenhum cliente aceita que seu produto seja entregue fora do prazo ou sem a qualidade prevista. Desconhecer que uma interrupção poderia acontecer, ou que não havia previsto algum fato não é desculpa nesse mundo globalizado, competitivo e dinâmico.
Uma organização deve ser sempre eficaz e eficiente em conformidade com o seu negócio. Logo, a continuidade do negócio passa a ser um fator estratégico e fundamental para o negócio de qualquer instituição, e Guindani (2008) acrescenta ser algo lógico e necessário. Essa afirmação é verdadeira porque todos os dias, meses e anos os sistemas computacionais sofrem ou estão sujeitos a sofrer várias interrupções. Conforme Garcia (2003), estudos nos Estados Unidos apontam que o número médio de paradas não planejadas ao ano é de 13, sendo quatro horas o tempo médio de uma interrupção. Uma organização pode ter um enorme prejuízo financeiro em relação às suas paradas de produção.
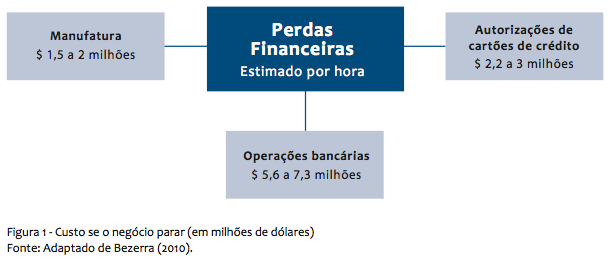
A figura a seguir apresenta uma visão macro de quanto uma empresa pode perder em dinheiro por hora. Podemos observar que o setor mais crítico são as operações bancárias, que podem perder até $ 7,3 milhões de dólares por hora.
")
Dessa forma, a continuidade do negócio deve ser planejada e exercida em uma organização que vise a mitigar os possíveis prejuízos que possam vir a ser causados. Segundo a Norma BSI 25999, a continuidade do negócio consiste na capacidade estratégica e tática de uma organização planejar para responder a incidentes e interrupções do negócio de forma que mantenha a sua capacidade operacional em um nível aceitável pré-definido pela organização.
Norma BSI 25999 – Desenvolvida para estabelecer o processo, princípios e terminologia da gestão de continuidade dos negócios.
Histórico
Apesar de a continuidade dos negócios ser uma atividade relativamente recente, isto é, considerado um domínio relativamente novo dentro do processo de gestão de riscos, ela surgiu, segundo IBM (1999), como um processo formal e atividade comercial na década de 1980, tratando principalmente da proteção dos antigos CPDs (Centrais de Processamento de Dados), base da estrutura de TI de uma empresa. O modelo centralizado de processamento de dados começou a sofrer alterações no início da década de 1990, dando espaço ao processamento distribuído e ao aparecimento da tecnologia cliente/servidor.
Logo depois, a TI passou a interligar todos os segmentos da organização, e o processamento de dados passou a ser fundamental ao negócio da organização. Com isso surgiram as preocupações e iniciativas para se manter o negócio ativo.
São criadas iniciativas para a manutenção da continuidade do negócio, como, por exemplo, o planejamento dos recursos da empresa, a gestão da cadeia de fornecimentos e a gestão das relações com os clientes. Isto é, hoje as empresas não podem funcionar sem o uso da TI em seu negócio (IBM, 1999).
A evolução do processo de continuidade de negócios é contínua, mantendo um planejamento das atividades e recursos sempre atualizados em conformidade com a evolução do negócio da organização. Em uma empresa que mantenha negócios 24 horas, 7 dias na semana e 365 dias ao ano (comércio eletrônico) o processo de continuidade de negócios é um parceiro para o seu sucesso. O histórico da evolução da continuidade do negócio e apresentado na Figura 2, a seguir.

Fatores fundamentais que contribuíram para a evolução da continuidade do negócio
Inúmeros acontecimentos e fatores foram considerados como impulsionadores da continuidade do negócio e da história da TI. Vejamos a seguir dois fatores relevantes.
Bug do milênio – Considerado uma ameaça sem precedentes na história, com data e hora marcadas para acontecer. As estimativas para as indenizações judiciais deveriam superar a marca de 1 trilhão de dólares. Os bancos investiram para adequar seus sistemas, o Citibank investiu uma quantia próxima a U$ 600 milhões para realizar adequação de seus inúmeros sistemas ao redor do mundo (GUINDANI, 2008).
11 de setembro de 2001 – 11 de setembro de 2001, uma data onde mundo parou para ver o desabamento do WTC, as torres gêmeas, símbolo de poder e supremacia norte-americana. Um atentado terrorista de tamanha projeção contra a maior potência mundial, os EUA. Inúmeras empresas a partir daquele momento deixaram de existir. Trouxe à tona uma série de variáveis no que diz respeito a vulnerabilidade das empresas a eventos que podem ameaçar suas operações. A realização de uma avaliação de risco, mesmo bem executada, não é garantia de segurança e mesmo um conjunto de planos bem estruturados não pode impedir a ocorrência de catástrofes, mas, no máximo, reduzir seus impactos.
Interrupções e desastres
Com evento acontecido no WTC em 11 de setembro de 2001, os conceitos de interrupções, desastres e continuidade de negócios sofreram algumas mudanças em seus fundamentos, apesar da base de seu conhecimento ter sido mantida. As ameaças, consideradas pela maioria dos gerentes/analistas de segurança da informação, sofreram uma evolução no decorrer dos anos.
Historicamente eram consideradas ameaças: incêndios; furacões; tornados, terremotos; inundações e apagões. Esses eventos, na maioria das vezes, podiam ser previstos, com base em estatísticas existentes, que tinham um valor quantitativo e compreensível. Entretanto, atualmente, além dessas ameaças existem outras como: cibercrime e queda no serviço; ataques terroristas; invasões; espionagem industrial; preocupação com infraestrutura; proteção de capital humano (epidemias). Essas possuem como características: intencionalidade, difícil de quantificar, não há limite de fronteiras para sua origem, não há como dimensionar a confiabilidade.
Entretanto, antes de se definir ou apresentar o que vem a ser interrupção e desastre, devemos apresentar o que vem a ser evento e incidente.
Evento é qualquer ocorrência observável em um sistema ou rede. Os eventos incluem, por exemplo, a conexão de um usuário a um arquivo, o recebimento de uma requisição web pelo servidor, entre outros. Os eventos adversos são aqueles que proporcionam uma consequência negativa, como inviabilizar o uso de sistemas, encher a rede de pacotes, uso não autorizado de pacotes (SCARFONE; GRANCE; MASONE, 2008 apud BRITO, 2010).
Incidente pode ser pensado como uma violação ou a ameaça eminente do desrespeito às políticas de segurança, políticas aceitáveis de uso ou práticas de segurança. Exemplos de incidentes: DoS (Deny of Service – ataque de negação de serviço), códigos maliciosos, acesso não autorizado ou uso inapropriado de sistemas.
Para melhor entender o que vem a ser interrupção e desastre, imaginemos o seguinte cenário:
Você chega ao trabalho pela manhã e visualiza um cordão de isolamento nos escritórios e uma fumaça saindo das diversas salas.
Por volta das 10h30 da manhã:
- Você não tem nenhum escritório disponível.
- Seus servidores estão danificados.
- Sua rede local, sua intranet e acesso à internet foram interrompidos.
- Os documentos de trabalho (ofícios, processos), clientes e críticos da empresa foram destruídos.
- Não se tem acesso ao prédio.
Analisando a situação apresentada, este cenário pode representar um sério desastre: a sua habilidade em conduzir o seu negócio foi interrompida.
Interrupção
A parada das funcionalidades dos negócios é chamada de interrupção. Interrupção também pode ser vista como um evento previsto (uma greve ou furacão) ou não (um blecaute ou terremoto), que cause um desvio negativo na esperada entrega e execução de produtos ou serviços, de acordo com os objetivos da organização.
Logo, as interrupções consistem em: • O período de tempo esperado que um serviço, sistema, processo ou função do negócio fique sem ser utilizado ou não acessível.
- Possuir um alto impacto para a organização.
- Comprometer as atividades necessárias para alcançar os objetivos da organização.
Durante uma interrupção, deve ser considerado:
- Qual é o impacto sobre o tempo?
- Quais são os processos críticos do negócio que são afetados?
- Se a empresa não pode alcançar os seus objetivos críticos, ela sobreviverá?
Além das considerações citadas, quais são os segmentos ou quem que será afetado pelas interrupções?
- Pessoas, por exemplo, os colaboradores da organização.
- As facilidades oferecidas pelo sistema computacional.
- As informações disponíveis para utilização, bem como sistemas, por exemplo, que dão o acesso às mesmas.
- Os clientes deixam de receber os seus produtos fornecidos pela organização.
Desastres
Os desastres podem possuir várias formas e, quando ocorrem, a melhor proteção é saber o que fazer. Desta forma, podemos dizer que ele é:
- Evento inesperado, calamitoso, que causa grande dano ou perda.
- No ambiente de negócios, qualquer evento que faz com que a organização perca as funções de negócio críticas por um pré- determinado período de tempo.
Como podemos afirmar que um evento é um desastre? O elemento-chave para essa análise é período de tempo em que a organização fica sem as funções de negócio críticas.
Por exemplo: Um site ficar fora do ar por 8 horas. Podemos considerar um desastre ou uma inconveniência?
Se considerar que o negócio da organização é baseado no negócio, que fica 24 horas, 7 dias na semana e 365 dias ao ano o site no ar, pode-se considerar um desastre.
Alguns exemplos de interrupções e desastres que aconteceram no decorrer dos anos:
- Mundo 1999 – internet –vírus de computador Melissa.
- Mundo 2000 – vírus de computador ILOVEYOU.
- Brasil 2001 e 2002 – corte de energia elétrica (apagão).
- Madrid 2004 – ataques terroristas.
- Indonésia, Sri Lanka, Índia e Tailândia 2004 – tsunami.
- Londres 2005 – ataque terrorista.
- Louisiana e Mississippi 2005 – furacão Katrina.
- Brasil 2009 – Serviços de banda larga ficam indisponíveis temporariamente em São Paulo causando danos às empresas que fazem uso do serviço.
- Brasil 2010 – Caos temporário na telefonia em São Paulo inviabiliza comunicação entre usuários, e no Rio de Janeiro não são permitidos interurbanos.
- Brasil 2011 – Agência de banco fica três dias sem comunicação na fronteira do Brasil, impossibilitando transações bancárias.
- Japão 2011 – Terremoto e tsunami.
Informações relacionadas a interrupções e desastres
A seguir são apresentadas algumas informações que reforçam a importância da continuidade do negócio em uma organização.
- Segundo o Gartner Group, cerca de 40% das empresas que sofrem um grave desastre ou uma longa descontinuidade não voltam a operar, e 33% das que voltam fecham em 2 anos.
- O U.S. Bureau of Labor cita que 93% das empresas que sofrem uma perda significativa de informações fecham dentro de 5 anos.
A Figura 3 apresenta uma visão do tempo máximo de interrupção que determinados tipos de empresa devem ter em mente. Acredita-se que até o valor citado em horas para cada segmento de negócios, conforme apresentado na ilustração, as empresas têm condições de mitigar as suas perdas e com isso retomar suas atividades de negócio normalmente.

Em uma pesquisa realizada em outubro 2007, com cerca de 250 empresas, sobre as principais causas de interrupções e desastres em organizações, apontou que ainda é a falta de energia o item de maior relevância (Figura 4). Assim, é possível inferir que o uso de equipamentos para reduzir o tempo de falta de energia é fundamental no processo de continuidade de negócios.

Interrupções e desastres que podem ser evitados
McAllister (2008) consultou os melhores profissionais para descobrir os 20 erros de TI, que são fórmulas inevitáveis para perda de prazo e detonação de orçamento. Neste texto serão citados 10 desses desastres que podem ser evitados.
1. Exagerar nas políticas de senhas
Uma política de senhas clara e bem aplicada é essencial para qualquer rede. Mas o excesso de rigidez é também uma faca de dois gumes, quando as exigências de senha são excessivamente complexas ou se os usuários são obrigados a mudar as senhas com muita frequência, as políticas podem ter efeito oposto ao desejado. Se os usuários precisam fazer muito esforço para recordar as senhas, acabam anotando-as em papéis que ficam em gavetas ou em adesivos colados no teclado dos laptops, anulando completamente o objetivo de segurança.
2. Administrar mal o data center
Os administradores de sistemas não são conhecidos exatamente pela sua organização. No ambiente de um data center esse quesito é essencial para o bom funcionamento. Para se ter uma ideia um cabeamento tortuoso, racks identificados incorretamente e equipamentos descartados podem causar grandes problemas, impactando negativamente no funcionamento, por isso, manter tudo organizado é necessário.
3. Perder o controle sobre ativos de TI
A gerência sênior faz um pedido: “A equipe de marketing precisa realizar consultas no banco de dados de produção”. É algo relativamente simples, no início você nega, mas acaba fazendo. Em pouco tempo você constata que consultas mal formuladas estão derrubando o servidor. Qual será sua próxima tarefa? Será resolver o problema de desempenho e acabar detectando a origem que surgiu com a realização da mudança anterior. Sendo assim, uma solicitação de mudança sem análise prévia pode gerar um impacto negativo em um ou mais processo(s) de negócio.
4. Tratar o legado como se fosse um palavrão, algo ruim
Os profissionais mais jovens talvez não gostem da ideia de que processos de missão crítica ainda estão sendo executados em sistemas da idade de seus avós. Entretanto, em geral, existe uma boa razão para TI valorizar os sistemas legados, pois sua modernização pode custar milhões em investimentos. De acordo com um estudo da IDC, o custo anual de manutenção para novos projetos de software normalmente alcança a casa dos milhões de dólares. Por isso, devemos considerar todos os pontos antes de iniciarmos um novo projeto.
5. Ignorar o elemento humano na segurança
Os administradores de redes de hoje têm acesso a um leque imenso de ferramentas de segurança. Mas como Kevin Mitnick afirma, o elo mais fraco em qualquer rede é o próprio ser humano. Por mais fortificada que seja a rede, ela continua vulnerável se os usuários tiverem livre acesso às informações, informando senhas ou outros dados confidenciais por telefone por exemplo. Por isso, a formação do usuário deve ser a base da política de segurança, evitando ataques de engenharia social. Nesta era de phishing e roubo de identidade a segurança é responsabilidade de todos os funcionários.
6. Criar funcionários indispensáveis
Por mais que seja confortador saber que um único funcionário conhece seus sistemas por dentro e por fora, não interessa a uma empresa permitir que profissionais de TI tornem-se realmente indispensáveis. Os funcionários que são muito valiosos em funções específicas, tendem a ficar presos ao cargo, não crescem profissionalmente e perdem novas oportunidades. Em vez de criar superstars especializados, você deve encorajar a colaboração e treinar seu pessoal para trabalhar com uma variedade de equipes e projetos. Logo, uma força de trabalho de TI diversificada, com múltiplos talentos, será melhor para o negócio.
7. Causar problemas em vez de oferecer soluções
Identificar riscos à segurança e possíveis pontos de falha são aspectos importantes do gerenciamento de TI, mas o trabalho não termina aí. Antes de relatar um problema, formule um plano de ação concreto para resolvê-lo e apresente ambos na mesma hora. Para ganhar apoio ao seu plano, explique sempre suas preocupações em termos do risco para o negócio – e tenha números que sustentem seus argumentos. Você precisa saber informar não apenas quanto custará resolver o problema, mas também quanto custará não resolvê-lo.
8. Logar como root
Um dos erros mais antigos e primários continua, os profissionais que normalmente fazem login através da conta do administrador – ou conta “root” – para tarefas mais insignificantes se arriscam a apagar dados valiosos ou até mesmo sistemas inteiros acidentalmente, mesmo assim, o hábito persiste. Felizmente, os sistemas operacionais modernos (entre eles o Mac OS X, Ubuntu e Windows XP em diante) ajudaram a conter esta prática porque vêm com os níveis mais altos de privilégio desativados por padrão. Em vez de rodar como root o tempo todo, os profissionais têm que entrar com a senha de administrador toda vez que precisam realizar alguma tarefa importante de manutenção do sistema. Pode ser um aborrecimento, mas é uma boa prática.
9. Tentar ficar na vanguarda
Programas betas são comuns e a tentação de se apoiar em ferramentas de ponta nos sistemas de produção pode ser muito grande. Não se arrisque instalando softwares sem homologação em servidores do data center, adote uma abordagem calculada. Mantenha-se informado sobre os últimos desenvolvimentos, mas não adote ferramentas novas no ambiente de produção até ter feito testes completos. Implemente projetos-piloto no nível departamental e certifique-se da existência de apoio externo. Você não quer ficar sem ajuda quando necessitar.
10. Reinventar a roda
Não existe melhor maneira de assegurar a agilidade de TI que se responsabilizar por suas necessidades de software. Frequentemente as empresas empregam desenvolvedores de software e acabam desperdiçando esses talentos em projetos errados. Você não deve criar seu próprio browser ou banco de dados relacional. O desenvolvimento interno de software deve ser limitado a projetos que proporcionem vantagem competitiva, o ideal é que se use softwares do mercado para funções que não são exclusivas do negócio. Na falta de um produto, comece com um projeto open source e ajuste-o para satisfazer os seus requisitos. Projetos de desenvolvimento redundantes só servem para distraí-lo dos verdadeiros objetivos corporativos.
Ação a uma interrupção e desastre
Acontecida a interrupção ou o desastre (incidente de segurança da informação), quais seriam os próximos passos? A figura a seguir apresenta uma visão dessas possíveis etapas que podem ser executadas durante todo o processo de gestão do incidente de segurança da informação.

Resposta ao incidente
A capacidade de responder a um incidente de segurança da informação torna- se cada vez mais necessário. Os frequentes ataques que comprometem, por exemplo, os dados do negócio de uma organização são diversos e eficazes quando não combatidos.
Os incidentes com códigos maliciosos são constantes, como: Blaster worm, SQL Slammer worm, dentre outros que interromperam ou danificaram milhões de sistemas e redes em todo o mundo.
Análise do incidente
• Responder aos incidentes de forma sistemática possibilita que medidas apropriadas sejam tomadas.
• Manter pessoal capacitado a recuperar de forma rápida e eficiente os incidentes de segurança, minimizando a perda ou o roubo de informações e perturbações aos serviços.
• Usar a informação adquirida durante tratamento de incidentes com o objetivo de preparar melhor a equipe para lidar com incidentes futuros e fornecer maior proteção para os sistemas e dados.
• Lidar de forma adequada com as questões legais que possam surgir durante os incidentes.
Após a análise do incidente de segurança chega-se a uma pergunta: O que fazer? Vale a pena tratar o incidente de segurança ou partimos direto para uma solução de continuidade do negócio?
Se a opção for partir para uma solução de continuidade, existe a necessidade de a organização implantar um processo de gestão de continuidade de negócios (GCN).
Gestão de continuidade do negócio
Acontecido o desastre, será que temos condições de saber o que deve ser feito, isto é:
- Onde reunir as pessoas?
- O que deve ser recuperado?
- As funções críticas de negócio?
- A sequência de ações para a recuperação?
- O tempo que existe para a recuperação?
- As pessoas necessárias para a recuperação?
- Requisitos offsite (fora da organização)?
Para que essas perguntas possam ser respondidas, o processo de gestão de continuidade de negócios deve estar implantado na organização. O processo de gerenciamento é responsável em identificar as possíveis ameaças a uma organização e os possíveis impactos às operações dos negócios no caso de essas ameaças se concretizarem.
Esse gerenciamento possibilita a obtenção e análise de informações e gera como produto final uma infraestrutura com base em uma estratégia e seu plano correspondente, o Plano de Continuidade de Negócios (PCN), que tem o objetivo de reagir, de forma efetiva, a uma interrupção não programada das atividades de negócio da organização. Estabelece uma estratégia com todos os procedimentos necessários à garantia do restabelecimento dos sistemas corporativos no menor espaço de tempo possível.
Fatores relevantes à continuidade de negócios
A continuidade dos negócios, que num primeiro momento parece algo lógico e necessário a qualquer empresa, é domínio relativamente novo dentro do ainda jovem setor da gestão de riscos corporativos. Isto porque, todos os dias, diversos sistemas sofrem interrupções, pessoas são vítimas de vírus, dados são obtidos ilegalmente e muitas empresas ficam de uma hora para outra sem poder operar normalmente devido à falta de energia elétrica.
A maioria das instituições tem suas atividades apoiadas por um conjunto de tecnologias que, se por um lado são responsáveis pelos expressivos níveis de eficiência, eficácia e produtividade, por outro determinam a existência de forte dependência das informações transacionadas e armazenadas em seus ambientes computacionais para a manutenção e geração de novos negócios.
Nesse contexto, todos os esforços possíveis, necessários à manutenção da disponibilidade das operações precisam ser despendidos.
As empresas devem, então, dispor de planejamento e de mecanismos adequados à pronta recuperação de suas operações, no menor tempo possível, como forma de precaver-se dos efeitos desastrosos de eventos que causem interrupções significativas em parte, ou mesmo em todos os seus processos de negócio.
Para que o processo de continuidade do negócio seja implantado, alguns aspectos devem ser levados em consideração:
- As ameaças – tudo aquilo que tem potencial para causar danos, ou seja, um incidente indesejado aos ativos de informação.
- Os riscos – é possível estar preparado para enfrentar todos os riscos existentes? A resposta à pergunta está diretamente relacionada ao tamanho do investimento que a empresa esteja disposta a realizar.

Para estarmos 100% protegidos ou seguros, o investimento seria tão alto que se tornaria inviável. Existe a necessidade de se realizar uma análise ou avaliação dos riscos para definir os possíveis e prováveis cenários que fazem parte do ambiente corporativo e que podem afetar a organização, seja com interrupções não previstas ou com desastres.
A análise ou avaliação dos riscos garante a redução dos possíveis impactos e permite direcionar os investimentos, buscando o desenvolvimento de uma estrutura de alta disponibilidade para os processos de negócio críticos. As interrupções que por desventura ocorrerem, sejam elas curtas ou prolongadas, afetarão a organização, causando impactos muitas vezes irreversíveis (BS 25999-1, 2006). Vejamos alguns termos e definições envolvidos nesse processo:
Impactos – Quais seriam as mudanças adversas no nível obtido dos objetivos de negócios?
Consequências – Quais são os prejuízos que a perda das propriedades de segurança da informação (confidencialidade, integridade e disponibilidade) pode trazer para o negócio da organização (perda da imagem, perda de oportunidades de negócio)? Para avaliar essas consequências devemos analisar o cenário de incidente durante um incidente de segurança.
Disponibilidade – Diretamente associado à operação praticamente ininterrupta das operações de TI que mantém as operações de negócio.
Funções do negócio – São estruturas conceituais idealizadas que servem para descrever a missão de uma organização.
Processo do negócio – É definido como a sequência completa de um comportamento de negócio, provocado por algum evento e que produz um resultado significativo para o negócio e que, de preferência, tenha foco no cliente.
Maximum Tolerable Downtime (MTD) – Consiste no tempo máximo que um negócio pode tolerar a indisponibilidade de determinada função. Funções diferentes terão MTDs diferentes. Caso a função seja considerada crítica, o seu MTD será pequeno.
MTD = RTO + WRT
Recovery Time Objective (RTO) – Consiste no tempo disponível para a retomada da entrega de produtos, sistemas e recursos interrompidos após um incidente (tempo de recuperação de sistemas).
Work Recovery Time (WRT) – Tempo pelo qual as funções do negócio voltam a trabalhar normalmente.
A Figura 7, sequência do incidente, propicia uma visão dos tempos MTD, RTO e WRT.

Referências
ASSOCIAÇÃO BRASILEIRA DE NORMAS TÉCNICAS. ABNT NBR ISO 31000. Gestão de riscos: princípios e diretrizes. Rio de Janeiro, 2009.
ASSOCIAÇÃO BRASILEIRA DE NORMAS TÉCNICAS. ABNT NBR ISO/IEC 24762. Tecnologia da informação – Técnicas de segurança – Diretrizes para os serviços de recuperação após um desastre na tecnologia da informação e de Comunicação. Rio de Janeiro, 2009.
BALAOURAS, S. DR Preparedness: Top 5 Myths and Truths. Disponível em: <https://h30406.
www3.hp.com/campaigns/2007/events/dora/images/webinar-slides-webcast-3.pdf>. Acesso em: 8 jan. 2012.
BEZERRA, E. K. Gestão da continuidade de negócios. Curso ministrado no 19o CNASI, Congresso Latinoamericano de Auditoria de TI, 2010.
BRITISH STANDARDS INSTITUTE. BS25999 – 1. Business continuity management – part 1: code of practice – BSI. Londres, 2006.
BUSSINES CONTINUITY INSTITUTE (BCI). Disponível em: <http://www.thebci.org>. Acesso em: 8 jan. 2012.
BRITO, I. V. da S. TRAIRA: uma ferramenta para tratamento de incidentes de rede automatizado. Graduação em Graduação em Ciência da Computação. Universidade Federal da Bahia, 2010.
CONTINUIDADE dos negócios: novos riscos, novos imperativos e uma nova abordagem. Companhia IBM Portuguesa, 1999. Disponível em: <http://www-05.ibm.com/services/pt/its/bcrs/gsopg40.pdf>. Acesso em: 7 jan. 2012.
DISASTER RECOVERY INSTITUTE INTERNATIONAL (DRII). Disponível em: <https://www.drii. org/>. Acessado em: 8 jan. 2012.
GARCIA, V. H. P. Continuidade e segurança: integrar para melhorar… Questera Report. 26 nov. 2003. Disponível em: <http://www.questera.com/QR20031126VH%20Continuidade%20
e%20Seguran%C3%A7a%20-%20Integrar%20para%20melhorar.pdf>. Acesso em: 10 jan. 2012.
GENERALLY ACCEPTED PRACTICES (GAP). Disaster Recovery Journal (DRJ). Disponível em: <http://www.drj.com/resources/resources/generally-accepted-practices.html>. Acesso em: 9 jan. 2012.
GUINDANI, A. Gestão da continuidade dos negócios. Integração, v. 1, 2008. Disponível em: <http://www.upis.br/posgraduacao/revista_integracao/gestao_continuidade.pdf>. Acesso em: 7 jan. 2012.
MCALLISTER, N. Vinte desastres de TI que você pode evitar: parte 1. Tecnologia, CIO, 6 out. 2008. Disponível em: <http://cio.uol.com.br/tecnologia/2008/10/06/vinte-desastres-de-ti-que-voce-pode-evitar-parte-1>. Acesso em: 8 jan. 2012.
NATIONAL INSTITUTE OF STANDARDS AND TECHNOLOGY. NIST 800-34. Contingency Planning Guide for Information Technology Systems, 2002.
Autor: Prof. Dr. Luiz Otávio Botelho Lento
Diego Macêdo
Sou bacharel em Sistemas de Informação pela Estácio de Sá (Alagoas), especialista em Gestão Estratégica da Tecnologia da Informação pela Univ. Gama Filho (UGF) e pós-graduando em Gestão da Segurança da Informação pela Univ. do Sul de Santa Catarina (UNISUL). Certificações que possuo: EC-Council CEH, CompTIA (Security+, CySA+ e Pentest+), EXIN (EHF e ISO 27001), MCSO, MCRM, ITIL v3. Tenho interesse por todas as áreas da informática, mas em especial em Gestão e Governança de TI, Segurança da Informação e Ethical Hacking.